Let's dive into how to make our website discoverable and more attractive when sharing in social media - with a cover image, proper title and short description.
This is the 5th post of the series - building personal static site with 11ty. GitHub Repo is here - jec-11ty-starter if you are a code-first person. 😉
Let's set up some global data before we start
We touched on global data in the previous post. Global data is data which, once defined, it is accessible in all project template files (e.g. Markdown, Nunjucks).
There are some common data we need for all pages, so let's create a new file under the default global data folder _data.
# folder structure
- src
- _data
- env.js # new file
Here is what our env.js file looks like.
// src/_data/env.js
const environment = process.env.ELEVENTY_ENV;
const PROD_ENV = 'prod';
const prodUrl = 'https://your-production.url';
const devUrl = 'http://localhost:8080';
const baseUrl = environment === PROD_ENV ? prodUrl : devUrl;
const isProd = environment === PROD_ENV;
const folder = {
assets: 'assets',
};
const dir = {
img: `/${folder.assets}/img/`,
}
module.exports = {
siteName: 'your site name',
author: 'your name',
environment,
isProd,
folder,
base: {
site: baseUrl,
img: `${baseUrl}${dir.img}`,
},
};
The code is quite straightforward. We set the ELEVENTY_ENV environment variable to dev or prod when we build the project (we set that in NPM scripts previously).
Depending on the value, we set other variables accordingly, then export it. These data can be accessed by any template files later. For example, we get the image base URL by calling env.base.img.
Create a base layout
We will be using the 11ty Layouts feature. A Layout is a reusable piece. As you know, we need to set the SEO (meta tags) and Google Analytics on every page. As a lazy developer, we don't want to copy-paste the same code every time. Layout can help with that.
_includes is the default layout directory (customizable). Let's create our first layout.
# folder structure
- src
- _includes
- base.layout.njk # create this file
File naming:
Please note that you can give your layout file any names. I followed Angular naming conventions personally - naming files with feature.type.js and dashed-case. I find it easier to search through the source files later.
Here is the base layout code to start with.
<!-- src/_includes/base.layout.njk -->
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport"
content="width=device-width, initial-scale=1.0">
<title>{{ title }}</title>
</head>
<body>
{{ content | safe }}
</body>
</html>
This base.layout.njk would be our skeleton (or you may call it "master layout") for all other templates. The title data will be provided by the child template later. The content data is the child template’s content. We escape the content by using the built-in safe filter.
Let's see how we can use this layout in our template file. the layout. Let's update index.njk:-
<!-- src/root/index.njk -->
---
layout: base.layout.njk
title: Home Page
---
<strong>Hello Eleventy!</strong>
We set the page layout to our newly created base.layout.njk. Open the page in browser now, you should see:
- The page title shown as "Home Page".
- The page shows Hello Eleventy! in bold - instead of literally "<strong>Hello Eleventy!</strong>" because we use the
safefilter to escape the content in the base layout.
Protip: Setting layout per directory
We can set the layout value in the Directory Data File root.11tydata.js. By doing this, we do not need to set layout in every template. All templates under the root directory will use base.layout.njk by default! (We covered this in the previous post.
Let's add Google Analytics
Let's start adding Google Analytics. Once you set up an account with Google Analytics, copy the JavaScript code snippet to our base layout.
The code should look something like this:
<!-- src/_includes/base.layout.njk -->
...
<head>
<!-- add these code in the head section -->
<script async
src="https://www.googletagmanager.com/gtag/js?id=your_tracking_id">
</script>
<script>
window.dataLayer = window.dataLayer || [];
function gtag() {
dataLayer.push(arguments);
}
gtag('js', new Date());
gtag('config', 'your_tracking_id');
</script>
...
</head>
...Erm... Not good enough
The above code works, but is not good enough because:
- We don't want to track the activities during development. We should enable that for production only.
- We might have different tracking id for different environments. For example, the beta environment. Hard-coded the tracking id here might not be ideal.
Let's enhance that, update our code above to the following:-
<!-- src/_includes/base.layout.njk -->
...
<head>
{% if env.isProd %}
<script async
src="https://www.googletagmanager.com/gtag/js?id={{ env.tracking.gtag }}">
</script>
<script>
window.dataLayer = window.dataLayer || [];
function gtag() {
dataLayer.push(arguments);
}
gtag('js', new Date());
gtag('config', '{{ env.tracking.gtag }}');
</script>
{% endif %}
</head>
...
With the above changes, the analytics code will be added to the page only if it's in production (env.isProd). We have also replaced the hardcoded tracking id with a new global data env.tracking.gtag. Add that in your env.js.
// src/_data/env.js
module.exports = {
...
tracking: {
gtag: 'your_tracking_id',
},
};
.
Cool, Google Analytics configuration is done. Try to build your code in dev mode npm run build and production mode npm run build:prod to see the different outputs.
Creating the robots.txt file
Robots.txt is a text file with instructions for search engine crawlers. Let's create one.
# folder structure
- src
- root
-robots.njk # new file
And here is the content of our robots.txt:
# src/root/robots.txt
---
layout: false
permalink: robots.txt
---
User-agent: *This will create the robots.txt file in our output directory.
Alternatively, you can name the file as robots.txt, but you might need to add the addPassthroughCopy setting in the .eleventy.js config file (covered in first post) because 11ty doesn't process text files by default.
Excluding pages for SEO
Sometimes we want to exclude pages for search index, like the /404 page. You can do that by adding the page URL in robots.txt.
However, there is another way to do it. We can add a meta tag in the base layout.
<!-- src/_includes/base.layout.njk -->
<head>
{% if ignore %}
<meta name="robots" content="noindex"/>
{% endif %}
</head>
...
For pages we don't want to index, we can set ignore to true in the page's Front Matter Data. Here is an example:
<!-- src/root/404.njk -->
---
layout: base.layout.njk
ignore: true
---
Page not found. Go home!
What are the tags for SEO?
At the minimum, we should set the title tag and meta tag description.
<!-- src/_includes/base.layout.njk -->
<title>{{ title }}</title>
<meta name="description" content="{{ desc or title }}">
In case there is no desc provided in the template file, we will use the title value as the description.
However, minimum is not good enough for social media sharing.
Social media meta tags
There are many social media meta tags you can set depending on how you want the data to display in the platforms. Read the specific social media documentation for the updated details.
I did the basic social media setup here:
- Support Twitter and Open Graph tags - Good enough, these tags work for popular platforms like Twitter, Facebook, Slack, LinkedIn, WhatsApp and more.
- Only one cover image in JPG format for all social media with size
1200 x 675 px- each social media platform requires a specific image size for optimal display. You may consider generating different cover images for that. I aim for basic configuration. The trick is to always set the main content at the center-ish location area of the cover image, so when the image is cropped by social media, main content will still be seen. (Try sharing this post in social media and test if my theory works 😉)
Here are the meta tags I used.
<!-- src/includes/base.layout.njk -->
<head>
<!-- Open graph -->
<meta property="og:title" content="{{ title }}">
<meta property="og:description" content="{{ desc or title }}">
<meta property="og:type" content="article">
<meta property="og:image" content="{{ cover }}"/>
<meta property="og:image:width" content="1200" />
<meta property="og:image:height" content="675" />
<!-- Twitter -->
<meta name="twitter:title" content="{{ title }}">
<meta name="twitter:card" content="summary_large_image">
<meta name="twitter:site" content="@yourUsername">
<meta name="twitter:description" content="{{ desc or title }}">
<meta name="twitter:image" content="{{ cover }}">
<meta name="twitter:creator" content="@yourUsername">
</head>
...For open graph meta tags, we need to set the width and height to make sure the cover image displays correctly every time someone shares the link (see the issue and explanation here).
Check the documentation for og:type and twitter:card, and pick the type that is most suitable for your content. I use Twitter summary_large_image because a big image looks great in a tweet.
Child templates will need to provide the cover data - cover image URL.
Here is the example of all the Front Matter Data that a child template should have set.
<!-- src/root/index.njk -->
<!-- omit the layout if it's already set in root.11tydata.js -->
---
layout: base.layout.njk
title: Home Page
desc: This is my home page.
cover: /assets/img/cover-image.jpg
---
<strong>Hello Eleventy!</strong>
Gotcha! No cover image shown in social media
Deploy your project. Try sharing the page URL in social media now.
Oops, no cover image shows in the thumbnail.
This is because the cover image URL must be absolute (e.g. https://your-site.com/assets/img/cover-image.jpg). You might thought this is an easy fix - by adding the base image url to the cover data like this:-
<!-- src/root/index.njk -->
<!-- Nice try, but this is not working! -->
---
title: Home Page
desc: This is my home page.
cover: "{{ env.base.img }}cover-image.jpg"
---
<strong>Hello Eleventy!</strong>
Nice try, but this is not working. 😆 (Said this to myself)
Turns out, we cannot have global data access and string interpolation in Front Matter Data (except the special case permalink, covered in previous post). That means your og:image and twitter:image are showing {{ env.base.img }}cover-image.jpg literally in the HTML.
Oh no, how to get around that?
To solve that, you can update the meta tag to include the base image URL.
<!-- src/includes/base.layout.njk -->
<head>
<!-- Open graph -->
...
<meta property="og:image" content="{{ env.base.img + cover }}"/>
<!-- Twitter -->
...
<meta name="twitter:image" content="{{ env.base.img + cover }}">
</head>
...With that, you only need to type the shorter image name in every child template.
Not good enough, for lazy developer
Let's face it, naming is hard. Typing the image URL manually in each template is time-wasting. It would be ideal if the cover data is:
- auto populated, in the format of cleaned-filename.jpg
- overridable in child template, in case we need to supply a different image
Here are the expected image names:-
| src | assets/img |
|---|---|
root/index.njk | root/index.jpg |
root/licenses.njk | root/licenses.jpg |
blog/2020-05-19-post-one.md | blog/post-one.jpg |
.
We can achieve this with the Global Computed Data eleventyComputed.js. In fact, we used that in our previous post. We can apply similar techniques here.
// src/_data/eleventyComputed.js
const env = require('./env');
module.exports = {
// add this cover data
cover: (data) => {
let img = data.cover || (data.page.filePathStem + '.jpg');
img = img.startsWith('/') ? img.substr(1, img.length - 1) : img;
return new URL(img, env.base.img).href;
},
...
};With the above code, we no longer need to enter cover data in every template file. Sweet! 😍
Social media content testing tools
You can test the code once it is deployed and publicly accessible. Various testing tools are offered by each platform - and each has its own fancy name...
- Twitter Card Validator - cards-dev.twitter.com/validator
- Facebook Sharing Debugger - developers.facebook.com/tools/debug
- LinkedIn Post Inspector - linkedin.com/post-inspector
So many different places to test! Yes. Once you set everything up correctly, then no more testing until the next time a social media platform decides to change their image display sizes... 😂
Sitemap
Sitemap is a good thing to have. You might not need one if you have linked your pages within your website. Crawlers are pretty good at discovering content automatically nowadays. Nevertheless, here is the code if you need to create one.
# src/root/sitemap.njk
---
layout: false
permalink: sitemap.txt
---
{%- for item in collections.all %}
{{ item.url }}
{%- endfor %}
Search engines accept sitemap in several formats. I am using a text file here, you may use xml. The collections.all data is an Eleventy Supplied Data. It contains all the pages we created in our project. We loop through each one and write the URL in the sitemap.
Protip: Logging and debugging
How to know what are the properties available in collections.all or item? We can use the filter log to examine the value. Here is how you can use it:
# src/root/sitemap.njk
{{ collections.all | log }}
Reload the page and check your dev console (where you run npm start). The collections.all data is logged.
Pretty handy! Use log for debugging and discovery.
Wait... something is not right
Browse to /sitemap.txt, there are a few things we need to fix:
ignorepages should be excluded - We marked404page asignore: true. We should exclude that from our sitemap.- URLs in sitemap should be absolute URLs - It's a sitemap requirement. Our URL now has no base URL.
- Remove
.htmlfile extension - The pages will get indexed by Google and show up in the search result. It's okay actually, but I don't like that. 😆 Let's remove that as well.
Here is the fix:
# src/root/sitemap.njk
---
layout: false
permalink: sitemap.txt
---
{# {{ collections.all | log }} #}
{%- for item in collections.all %}
{% if not item.data.ignore %}
{{env.base.site}}{{ item.url | replace('.html', '') }}
{% endif %}
{%- endfor %}
Another way to fix this would be creating your own collection to filter out the unwanted pages, but we won't cover this for now. There is a lot to learn already!
Nice. Browse to /sitemap.txt page again, you should see all URLs are absolute and cleaned! Go ahead and submit that to Google Search Console and probably the Bing Webmaster Tools too (which I did, because why not)!
Bonus: Adding Structured Data
Google has a detailed explanation on structured data. Adding structured data helps crawlers to understand your content more, and there would also be a possibility that your page would show up nicer in the search result.
We can define structured data with script format JSON-LD. Both Google and Bing support that. We don't need structured data for every single page, only the main content (blog posts, presentation decks) will do, in my opinion (but I am not an SEO expert).
Again, we don't want to add the JSON-LD script in every content page manually. One way to solve this is to do something similar to the ignore. We can achieve this by using a new Front Matter Data, for example isSupportStructuredData, to check the boolean value and toggle the script accordingly. However, let's not overuse the Front Matter.
Using a new layout would be a better option for our case. Let's create one and I will explain later why it is better.
# folder structure
- src
- _includes
- writing.layout.njk # new fileUpdate all our blog posts to use the writing layout. To save time, we can just add that once in the blog.11tydata.js file.
// src/blog/blog.11tydata.js
module.exports = {
layout: 'writing.layout.njk',
...
};
The good thing about layout is - it is chainable. writing.layout.js extends from the base layout (so we don't need to define those meta tags again 😃).
Alright, here is our writing layout with structured data.
<!-- src/_includes/writing.layout.njk -->
---
layout: base.layout.njk
---
<!-- the content -->
<main>
<article>{{ content | safe }}</article>
</main>
<!-- the structured data -->
{% set absoluteUrl = env.base.site + (page.url | replace('.html', '')) %}
<script type="application/ld+json">
{
"@context": "http://schema.org",
"@type": "Article",
"@id": "{{ absoluteUrl }}",
"mainEntityOfPage": {
"@type": "WebPage",
"@id": "{{ absoluteUrl }}"
},
"url": "{{ absoluteUrl }}",
"headline": "{{ desc }}",
"description": "{{ title }}",
"audience": "web developers and designers",
"image": {
"@type": "ImageObject",
"url": "{{ cover }}",
"height": 675,
"width": 1200
},
"dateCreated": "{{ date }}",
"datePublished": "{{ date }}",
"dateModified": "{{ date }}",
"articleSection": "Blog",
"author": {
"@type": "Person",
"name": "{{ env.author }}",
"image": {
"@type": "ImageObject",
"url": "{{ env.base.img }}your_photo.jpg",
"height": 1024,
"width": 1024
},
"url": "{{ env.base.site }}"
},
"publisher": {
"@type": "Organization",
"@id": "{{ env.base.site }}",
"name": "{{ env.siteName }}",
"url": "{{ env.base.site }}",
"logo": {
"@type": "ImageObject",
"url": "{{ env.base.img }}your_photo.jpg",
"height": 1024,
"width": 1024
}
}
}
</script>
Structured data is lengthy. Luckily we just need to write it once in writing layout, not every post.
Use the writing layout in our blog post. Here is how our blog post look like:
<!-- src/blog/2020-05-19-post-one.md -->
---
title: A day of my life
desc: Story of a relaxing day.
date: 2020-05-20
---
I do nothing and sleep all day.
Layout data is inherited from blog/blog.11tydata.js and cover image is defined in global data. We don't need to add those in the templates again.
View the script output in DevTools. Check if the data populated correctly.
Why is layout a better option in this case?
The writing layout does not only have structured content data, but it has some specific CSS for styling as well.
It is good for us to not mix it with base.layout.njk. Keep the base layout clean.
How to test it?
You can validate the structured data with the Google structure data testing tool, even during development. Select the "code snippet" option and paste your JSON-LD script there.
There is a handy feature in Chrome DevTools to help you to copy the script easily - in the Elements tab, right click on the script element > select Copy > Copy element.
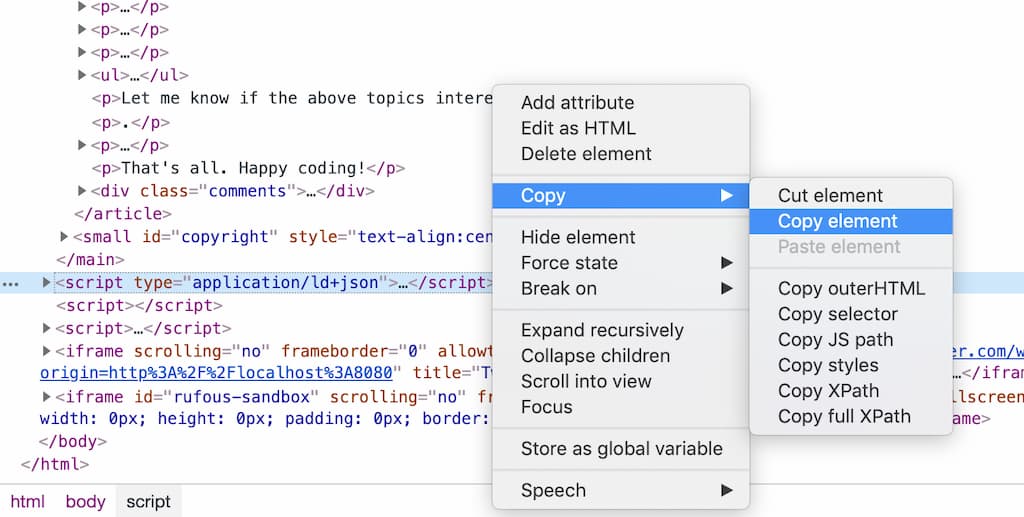
There you go, the script is in your clipboard!
But.. how to know what structured data to set?
The fact is, I don't know either. I use DevTools to inspect the top article sites like Medium.com and Scotch.io to learn how they configured the structured data. That's how I came out with the above script. 😂
I also referred to the schema.org website to see what are the fields available for each entity.
Bonus: Any other to-dos to enhance SEO?
SEO is a big topic. While I might not be an expert, here is a few things that can impact your site ranking:
Low hanging fruits:
- Site performance - Page speed is one of the ranking factor. Make sure your page loads fast. Use Lighthouse (Chrome DevTools > Audits panel) to detect and fix potential performance issues. Other tools helped as well - PageSpeed Insights or WebPagetest.
- Responsive layout - Page should be mobile friendly, and provide positive user experience (UX). Better UX leads to longer "time spent on page", and thus raise the page ranking. Test your site with Mobile-Friendly Test.
Require more effort:
- Adding AMP Page and Facebook Instant Article might help as well.
- Backlink - When reputable sites link to your page, your page ranks higher because it represents a "vote of confidence".
Bonus: Search your site URLs
You can search for all your site URLs to check if your pages are indexed in search engine.
Type site:your_domain_url in Google or Bing. You will see a list of your indexed pages. For example, this is the result when I google site:jec.fish.
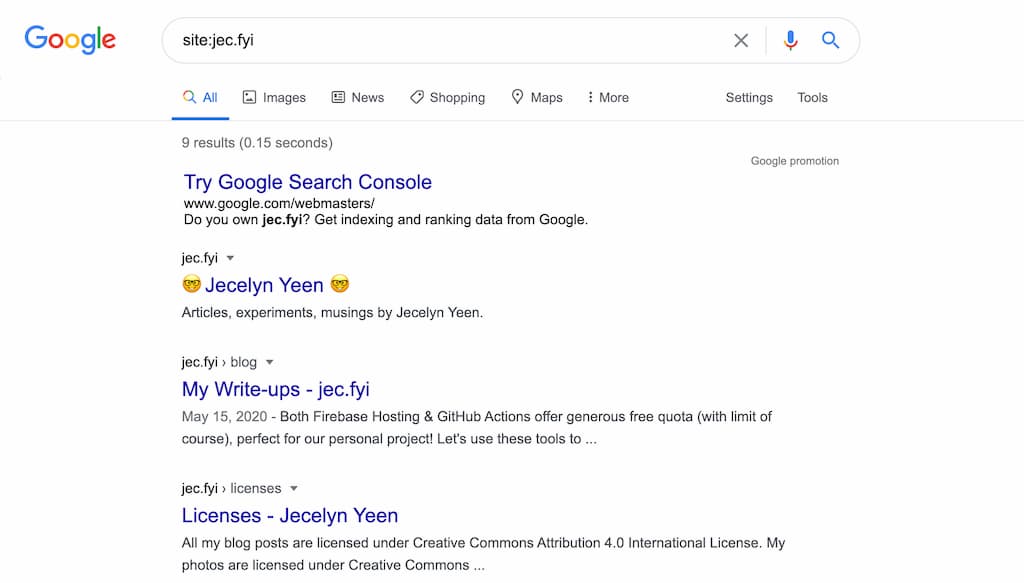
Alternatively, you can view it in Google Search Console and Bing Webmaster Tools.
Alrighty, what's next?
Yay! We have learnt quite a bit in this post! From setting up Google Analytics, meta tags, and sitemap, to structured data, and various testing tools. Oh, we have also learnt about how to use layouts and global data!
All these efforts are mostly one time. Get it right and you won't need to worry about it anymore (until something suddenly breaks, heh 😝).
This is how I set up the SEO of my site jec.fish as well.
In the coming posts, I plan to write about more on how I built my website with 11ty:
- Building Personal Static Site with Eleventy ✅
- Setting up GitHub Actions and Firebase Hosting ✅
- Customizing File Structure, URLs and Browsersync ✅
- Automating Image Optimization Workflow ✅
- Setting up SEO and Google Analytics ✅
- Minifying HTML, JavaScript, CSS - Automate Inline ✅
- How many favicons should you have in your site? ✅
- Creating Filters, Shortcodes and Plugins ✅
- Supporting Dark Mode in Your Website ✅
- and probably more!
Let me know if the above topics interest you.
.
Here's the GitHub repo for the code above: jec-11ty-starter. I'll update the repo whenever I write a new post.
That's all. Happy coding!
Have something to say? Leave me comments on Twitter 👇🏼
Follow my writing: @jecfish